|


Perception in Virtual Environments
Three-dimensional computer graphics is completely accepted as a required adjunct to scientific computing. The use of 3D has swept the workstation world and, thanks to PC accelerator cards, is now moving onto the desktop as well. Because of VRML and programming language APIs such as Java 3D, three-dimensional displays are also sweeping the World Wide Web. We all welcome this, but do we know exactly what it is we are welcoming? We have considerable experience using 3D graphics in scientific visualization, but we have very little understanding of what aspects of those 3D graphics give us the most perceptual benefit. Up until a short time ago, we didn’t really care. Everything seemed to be working fine. Then we got one of those surprises that sometimes slip by unnoticed if you aren’t paying close attention.
In these communities, it is nearly universally accepted that with sufficiently good pixel resolution, color resolution, lighting models, hidden surface removal, shading, texturing, fast hardware, and binocular displays, observation of a virtual object will yield as much insight as observation of its physical counterpart . Our qualitative experience now says that this is not true. Does this mean that there is some aspect of current 3D graphics practice that is not representing reality adequately? We need to discover if this is really the case, and if so, what precisely is missing in the graphics systems?
In this project, we tested the effectiveness of various depth-cues on the perception of 3D scenes. In order to keep this study tractable, we did not consider all perceptual cues, but only those that differed between the synthetic scenes and the real scenes presented by the physical models.
Perceptual Cues Tested
There are several depth cues that are approximated when creating a synthetic scene, and thus could lessen the insight obtained from a 3D synthetic image compared with the insight obtained from a real model. We have chosen to focus on six of them that are of particular interest. Four of these, spatial resolution, stereopsis, lighting model, and shadows, can be varied when creating a synthetic scene. The fifth item, focus accommodation, cannot be replicated in a synthetic scene display, and thus is a major candidate for being the fundamental difference between viewing a real and a virtual object. The sixth cue, for which we only suggest a pilot experiment, is the relation between observer movement and depth perception.
Spatial Resolution
Anyone who has experienced VR knows that currently the screens
used in VR head mounted displays do not have enough resolution for the
small distance to the eye. The imagery looks blocky, the pixels and scanlines
are visible, and it is difficult to suspend disbelief. We will test the
perceptual effectiveness of duplicate synthetic scenes, half that have
been created at a resolution whose pixels subtend less than one arc-minute
of angle when viewed by the subjects and half whose pixels subtend much
more.
Surface Lighting Model
![]()
This effect is known as radiosity. The radiosity mathematical model allows
all surfaces to contribute light to all other surfaces. Again, in a nutshell,
this equation says that the light coming off a particular surface i is
equal to the light created by that surface (if, for example, it is a light
source) plus the light reflected from all other surfaces. The light reflected
from all other surfaces depends on their light intensity times a “shape
factor” Fji that describes how much of the light from surface j
arrives at surface i. Details, again, are available in [FOLEY90].
Shadows
Our visual system was wired at birth to use shadows as a way to interpret
the world around us. Indeed, as newborns, we saw the world as shadows
before we saw it as individual details. In synthetic scenes, shadows can
play an important role. Shadows serve to show how far apart surfaces are.
If we view a synthetic scene and see object A sitting on top of flat surface
B, we do not immediately know if A is resting on B or hovering up in the
air above B. Other depth cues, such as perspective, do not always help
here unless we already know the relative sizes of the elements in the
scene. But, the addition of a shadow cast from A falling on B will tell
us much more about the spatial relationship between the two.
Binocular Vision (Stereopsis)
Binocular vision functions as it does because of the convergence phenomenon.
Our two eyes rotate semi-independently left-to-right in order to both
be aiming at the visual target. Targets close to the viewer require the
left-to-right rotation angles of the eyes to be quite different. In the
limit, as an object sits at the nose of the viewer, the eyes are crossed.
Objects far away require left-to-right rotation angles that are nearly
the same.
Focus Accommodation
When the human eye views a real 3D scene, it does not retain one focal
depth. In the same way that the focus ring on a camera lens has to be
constantly rotated to keep a moving target in focus, the distance from
the eye’s lens to the retina wall is constantly being changed to
accommodate, or keep in focus, objects that exist at varying distances
from the viewer. Because this happens so automatically, we are seldom
aware of it.
Graphics systems, even binocular VR systems, rely on the synthetic image
being formed on a flat piece of glass. Thus, no graphics system can replicate
focus accommodation now, and none ever will. This means that no matter
how good the quality of VR systems becomes, they will never exactly match
the full perceptual effectiveness of a real 3D object. The only question
would then be, how close can they come?
The Experiments
Our objective in the set of experiments we conducted
was to empirically compare the adequacy of:
• different image generation models.
• different viewing conditions
Which of these enables better recovery of task relevant 3D information? Our overall plan was to empirically establish the best generation and viewing conditions and compare performance in this best case virtual scenario with performance in ordinary physical scenarios. We began by comparing radiosity and shadow models. We then compared viewing conditions. Once we had an idea of the best generating and viewing conditions we combined the best of each to produce an “optimal” synthetic image and compared performance using that optimal synthetic image with performance using real images viewed in normal physical conditions. To increase the generalization of our findings we tested every condition on two tasks. These tasks were selected because they require extracting information about 3D shape of the sort involved in solving the type of problems worked on by scientific visualizers who provided our anecdotal information. The two tasks were:
1. Depth Discrimination Task
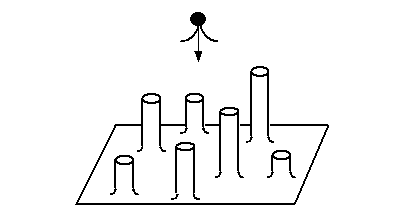
Subjects were shown a bulky object with several regular cylindrical protrusions,
as shown below, each labeled to permit easy description. Each protrusion
had the same diameter, but varied in height. The subject viewed the object
in a stationary position and was asked to rank the heights of the protrusions
in order from lowest from the surface to highest. Speed and accuracy of
response were measured.
2.
Mental Rotation Task
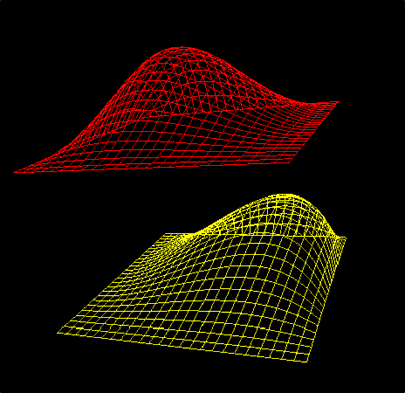
Subjects were shown two objects, each was a bumpy and molecule-like creating
a surface of hills and valleys. A simplified version of this is shown
below.. The task was to decide whether the two objects have complementary
surfaces, that is, whether they can be oriented in some way so that they
fit hand in glove. This task is inspired by the mental rotation task of
Shepard and Metzler (1971). Again the objects were stationary and not
under subject control. Speed and accuracy of response were measured.
|
|


|
